
The aim of this project was for me to get some experience with computer vision problems. I found that the results were quite fun, so I decided to tidy up the code and deploy it. You can access the deployed Streamlit dashboard here.
Problem description#
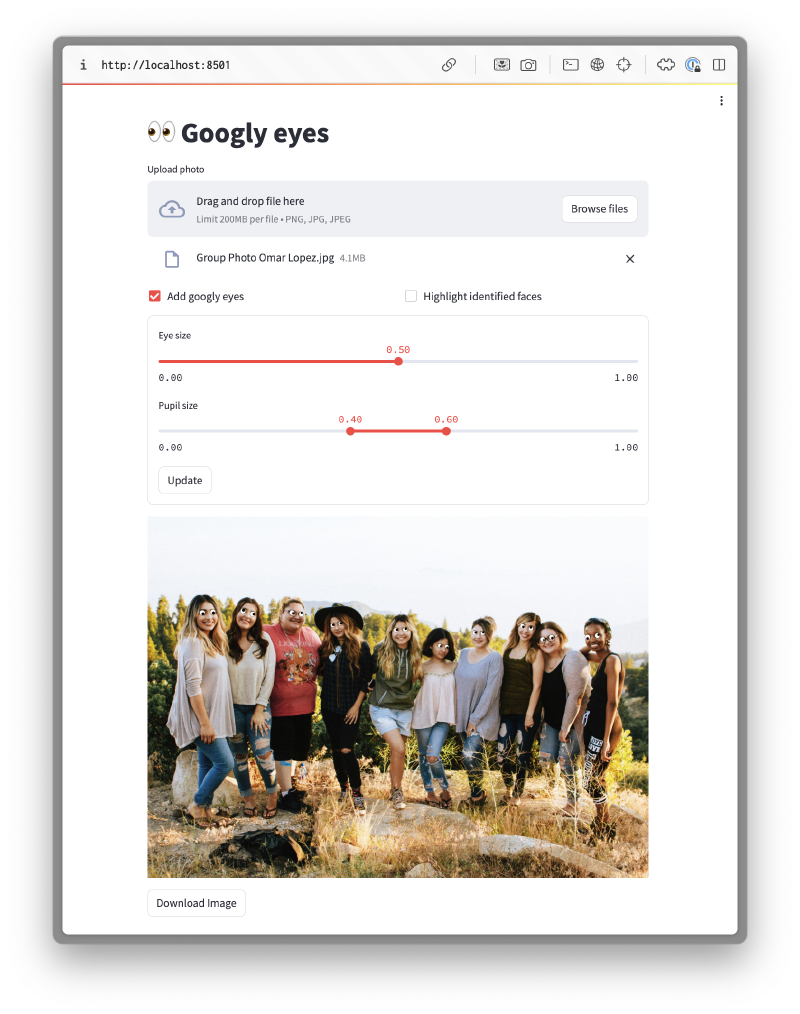
The objective was to create a system which could automatically overlay googly eyes on top of people’s actual eyes in a given photo as shown below. I wanted it to work even if there was more than one person in the photo.
Simplifications#
To simplify the problem, I made the following assumptions:
- We only wish to detect human faces (and not pets)
- The faces are approximately aligned with the vertical axis of the photo, so the face detection step does need to be robust to misalignment
- The people will be facing the camera in the photos (or close to it), so we do not need to consider 3D geometric effects when placing the eyes
Project plan#
This problem can be decomposed into the following steps:
- Build a build to identify eyes in photos of people
- Generate Googly eyes with random shapes and sizes
- Create a server which processes HTTP requests
- Create a UI to interact with the service
I will now explain how I achieved each of these steps.
Eye identification#
This is an object localisation problem since:
- We need to identify the locations of eyes in the image
- We only need to classify a single class of objects
The most obvious approach for identifying eyes is to use a CNN, trained on pre-labelled images of people’s faces.
Training a custom model#
The first option I considered was to implement my own model. I could think of two possible architectures for localising the eyes:
- Train a model to identify eyes directly from the photo
- Use a 2-stage identifier as follows:
- Stage 1: Identify faces
- Stage 2: Identify eyes from each face
The latter approach has the potential to be more robust, since the eye identification model only has to consider faces, so is less likely to be “tricked” by other features in an image. However, it would be slower since two models need to be evaluated.
In either approach, we can make use of pre-trained image classification models for the main trunk of the model since:
- They are often trained in datasets with people in so already have some capability to recognise faces and facial features
- The input layers of the network identify “features” which will transfer well to different applications
The dataset we use to train network is very important. We must ensure that it is representative of the sorts of images which the users will upload. Therefore typical datasets for biometric identification would not be suitable. Instead we should use a dataset with photos in more natural environments. The LFW dataset seems most suitable.
Pre-trained models#
Since the task of recognising faces and facial features is a very common one, we can make use of pre-existing models to perform this step for us. After a brief search, I came across many open-source models. The two most performant models are listed below.
| Model | Paper | Source code |
|---|---|---|
| MTCNN | PyTorch / TensorFlow | |
| RetinaFace | PyTorch / TensorFlow |
RetinaFace generally performs slightly better, likely because it was trained with an augmented set of labels including 1k 3D vertices.
I chose to make use of the existing RetinaFace model, since this model would likely be much more accurate than any model I could train, without spending a lot of time on data processing and model training. This also allowed me to focus my time on the other aspects of the system.
I converted the Tensorflow model to use the Tensorflow-lite runtime instead. This required updating the model and pre-processing steps to use fixed image dimensions. This has two main advantages:
- It significantly reduces the size of the docker images
- It reduces execution time
Googly-eye generation#
Once we have detected the position of the eyes, we need to add the googly eyes in the correct location. I used the ImageDraw module to perform the image manipulation and draw the eyes. However, I still needed to decide how to size the eyes and where to place the pupils.
Eye size#
To ensure that the googly eyes are of an appropriate size, independent of image dimensions or the distance from the face to the camera, I computed the eye-to-eye separation distance for a given face from:
$$ \Delta_{eye2eye}=\sqrt{(x_r-x_l)^2+(y_r-y_l)^2} $$
where \(x_r, y_r\) are the pixel co-ordinates of each eye. I then set the radius of the googly eyes \(r_e\) by:
$$ r_e =\gamma\frac{\Delta_{eye2eye}}{2} $$
where \(\gamma\) is a scaling parameter in the range \(0<\gamma<1.0\). I set the default value to 0.5.
Pupil size#
The pupil size \(r_p\) was set based on the eye size from:
$$ r_p=\lambda r_{e} $$
where \(\lambda\) is a random variable sampled from the following distribution:
$$ \lambda \sim U(\lambda_1, \lambda_2) $$
where the default values for the parameters \(\lambda_1\) and \(\lambda_2\) were set to 0.4 and 0.6 respectively.
Pupil position and orientation#
To randomise the position of the pupil, the position was set by the following equation:
$$ x_p = x_e+ (r_e-r_p) \sin \theta $$
$$ y_p = y_e+ (r_e-r_p) \cos \theta $$
where \(\theta\) is the random orientation sampled from the following distribution:
$$ \theta \sim U(0,2\pi) $$
Local development#
The first stage was get the system running locally on my machine. This was split into two components:
- Server to handle HTTP requests and perform the image manipulation
- Dashboard acting as a user-friendly interface for making requests to the server
Server#
In order to handle the HTTP requests, I created a server using Flask. I created a single end-point specified as follows:
| Body | Response |
|---|---|
| Image | Edited image |
| Googly eye parameters | Locations of detected faces |
Both the body and response of the post request are in JSON format. In both cases, the photo is serialized as a Base64 string. Additional parameters for the eye and pupil size can be included in the request body. This allows the user to override the value of any of these settings to personal preference. The locations of the faces are returned for debugging purposes.
The server runs through the following steps:
- Deserialize the request body to extract the image and parameters
- Call the RetinaFace model to identify the faces in the images
- Overlay googly eyes on each of the faces
- Serialize the edited image and combine with the identified faces to form the response body
All image processing and manipulation was then performed in memory, so no images are ever stored to disk on the server.
When running the server in Docker, I used the Waitress web server. The Python dependencies are managed using Poetry and the server is encapsulated within a Docker container.
Dashboard#
To allow the user to interact with the server more easily, I build a minimal dashboard using Streamlit which allows the user to:
- Upload a photo
- Adjust parameters for the googly eyes
- Download the modified photo
The dashboard then performs the following steps:
- Gets the settings from the information entered by the user
- Makes the HTTP request to the server to add the googly eyes
- Overlay the identified faces for debugging purposes (if requested)
- Displays the result and adds a download link
The dashboard is hosted in a separate Docker container, with its own smaller set of dependencies using Poetry. The network connection to the server is configured using Docker compose.
Cloud deployment#
Now that I had got everything working locally, the next stage was to deploy it to the cloud.
Server#
Since the server was already contained within a Docker container and contained only a single end-point, it was quite simple to convert it into an AWS Lambda function. I used an AWS function URL to expose the AWS Lambda, with IAM authentication. This had the advantage that I did not need to manage any compute resources.
The main challenge I ran into was the the AWS Python Lambda Docker images were based on a version of Amazon Linux with out-of-date system dependencies for the version of Tensorflow I was using. To get around this, I built a custom image using the process described here, based on a Debian-based Python image from Docker Hub.
I found that the AWS Lambda required 3GB of RAM to run the RetinaFace model reliably. However, it is quite slow due to the server being quite underpowered, and therefore needs a large 60s timeout.
Dashboard#
Unfortunately the Streamlit dashboard I built already in the dashboard subdirectory could not be deployed to Streamlit cloud as-is. This is because the dashboard used uses files from the shared common directory but Streamlit cloud dashboards only have access to files in the same directory.
To get around this limitation, I created a wrapper module app.py at the root of the repo, which in turn calls the existing dashboard code. This ensures that the deployed dashoard has access to the entire repo. This setup supports both local development and cloud deployment, without any code duplication.
The architecture of the production system is shown below.
graph TD subgraph Streamlit Cloud subgraph Wrapper module A end end E[User]-.->A A[Dashboard]--Image-->B[Lambda Function] B--Edited image-->A B--Image-->D[RetinaFace] D--->F F[Googlifier]--Edited image-->B subgraph AWS subgraph Docker container B D F end end